By the end of this course, you will be able to:
Training a large language model costs millions of dollars. Before this paper, there was no principled way to decide how to spend that budget. This lesson frames the problem and introduces the surprising answer.
Imagine you are a chef with a fixed grocery budget. You could buy expensive wagyu beef and cook it briefly, or buy cheap chicken and marinate it for hours. Without knowing how ingredient quality and cooking time affect the final dish, you are guessing. You might assume the best strategy is to cook whatever you buy until it is done – fully cooked, no shortcuts.
Training language models poses the same dilemma. Your “budget” is compute – GPU hours, which translate directly to money and electricity. You have three knobs to turn:
Before this paper, the standard practice was to pick a model size, collect as much data as possible, and train to convergence – keep going until the loss stops decreasing. The 2020 Kaplan et al. paper discovered this is wrong. Spectacularly wrong.
The paper found that:
This last finding was revolutionary. It meant that most training runs in the field were wasting compute on small models trained too long, when they should have been training much larger models for much shorter.
Suppose two teams each have a budget of \(10^{19}\) FLOPs (roughly 1 PF-day – one petaflop of computation sustained for one day).
Team A (conventional wisdom): Trains a 125-million-parameter model to convergence over 300,000 steps. The model fully converges, achieving its best possible loss of 3.4 nats.
Team B (scaling law guidance): Trains a 1.3-billion-parameter model for only 5,400 steps, stopping far before convergence. The model achieves a loss of 2.8 nats – significantly better.
Team B’s model is 10x larger, trains for 55x fewer steps, and gets a 18% lower loss. The key insight: the loss improvement from a bigger model outweighs the loss penalty from not converging.
Here is why this works intuitively. A small model, no matter how long you train it, has a floor – it cannot represent patterns beyond its capacity. A large model reaches a good loss quickly because it has more capacity, even if it has not yet squeezed out every last bit of performance. Since each training step costs proportional to \(N\) (bigger models = slower steps), the budget is spent more efficiently on a big model trained briefly.
Recall: What are the three knobs you can turn when allocating a compute budget for language model training? Which one does this paper argue should get the largest share of increased compute?
Apply: Team C has \(10^{20}\) FLOPs (10 PF-days). Using the paper’s finding that optimal model size scales as \(N \propto C^{0.73}\), if Team B (at \(10^{19}\) FLOPs) optimally used \(1.3 \times 10^9\) parameters, what is the optimal model size for Team C? (Compute \(10^{0.73} \approx 5.4\).)
Extend: The paper says “convergence is inefficient.” But in practice, many companies still train models to near-convergence. What practical reasons might override the theoretically optimal strategy? (Hint: think about hardware constraints, wall-clock time, and the difference between total compute and parallelism.)
Power laws are the mathematical foundation of everything in this paper. This lesson teaches you to recognize, interpret, and compute with power laws, which is essential for all subsequent lessons.
A power law is a relationship of the form:
\[y = a \cdot x^b\]
where \(a\) is a scale constant and \(b\) is the exponent (also called the slope on a log-log plot). The defining property of a power law is scale invariance: if you multiply \(x\) by some factor \(k\), then \(y\) changes by a factor \(k^b\), regardless of where you started. Doubling \(x\) always multiplies \(y\) by \(2^b\).
Think of it like compound interest. If a power law says “doubling the input reduces the loss by 5%,” then that 5% reduction applies whether you go from 1 million to 2 million parameters, or from 1 billion to 2 billion. The percentage improvement per doubling is constant.
Log-log plots make power laws easy to see. Take the logarithm of both sides:
\[\log y = \log a + b \cdot \log x\]
This is a straight line with slope \(b\) and intercept \(\log a\) when you plot \(\log y\) vs. \(\log x\). Any straight line on a log-log plot is a power law.
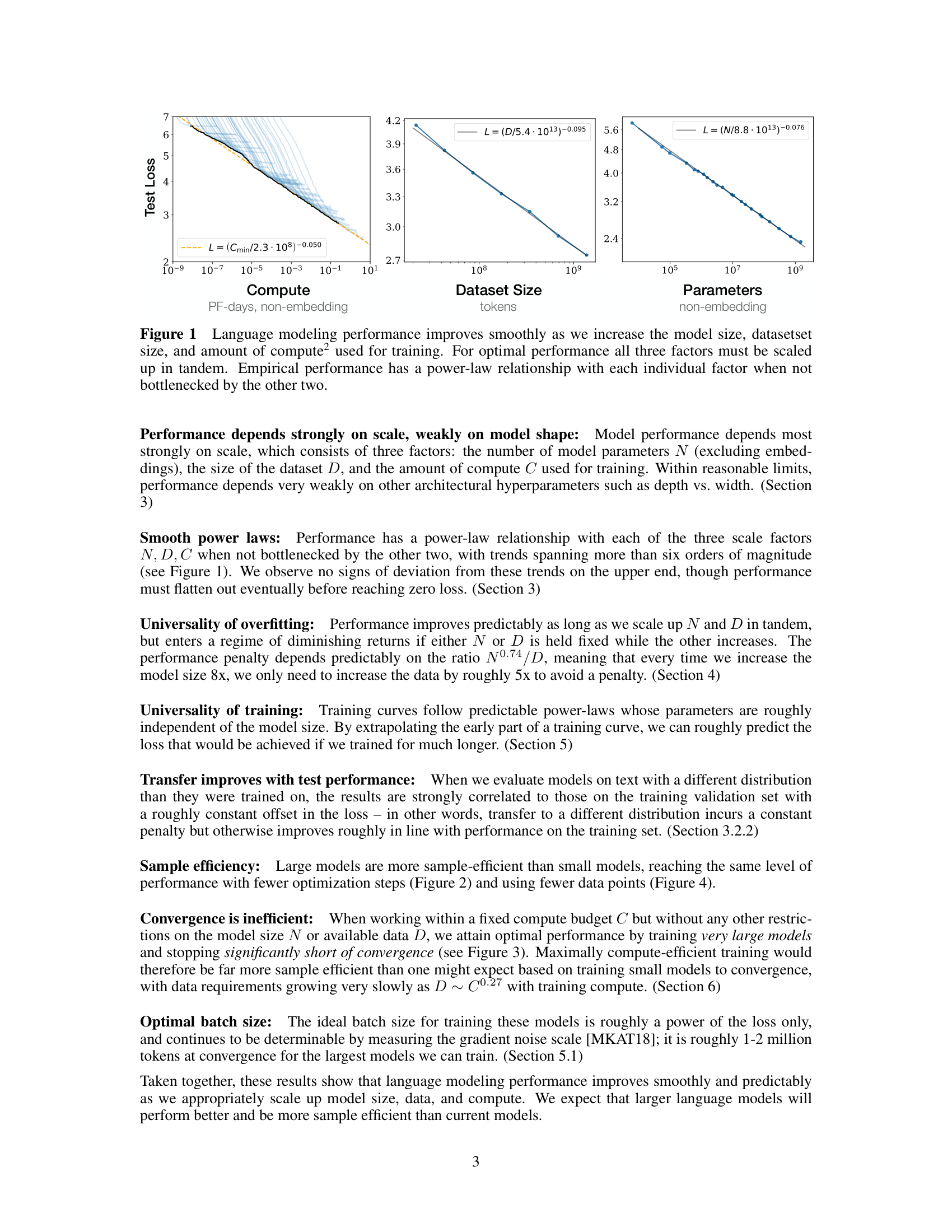
Figure 1 from the paper: language modeling performance improves as a smooth power law when scaling compute (left), dataset size (center), or model parameters (right) independently. Each relationship appears as a straight line on a log-log plot.
The scaling laws paper writes power laws in a specific form:
\[L(X) = \left(\frac{X_c}{X}\right)^{\alpha}\]
where \(L\) is the loss, \(X\) is the variable (model size, data, compute), \(X_c\) is a scale constant, and \(\alpha\) is the exponent. The loss decreases as \(X\) grows because \(X_c / X\) gets smaller. The exponent \(\alpha\) controls how fast.
A crucial subtlety: the exponents in this paper are small. \(\alpha_N \approx 0.076\) means doubling the model size reduces loss by a factor of \(2^{-0.076} \approx 0.949\) – only about a 5% improvement. This means you need orders of magnitude of scaling to see large improvements. A 10x increase in parameters gives \(10^{-0.076} \approx 0.84\) – a 16% improvement. A 1000x increase gives \(1000^{-0.076} \approx 0.59\) – a 41% improvement.
Let’s practice reading a power law. The model-size scaling law is:
\[L(N) = \left(\frac{N_c}{N}\right)^{\alpha_N} \quad \text{with } N_c = 8.8 \times 10^{13}, \; \alpha_N = 0.076\]
Question: What loss does a 10-million-parameter model achieve?
\[L(10^7) = \left(\frac{8.8 \times 10^{13}}{10^7}\right)^{0.076} = (8.8 \times 10^6)^{0.076}\]
Take the natural log: \(\ln(8.8 \times 10^6) = \ln(8.8) + 6 \ln(10) = 2.175 + 13.816 = 15.991\)
\[L = e^{0.076 \times 15.991} = e^{1.215} = 3.37 \text{ nats}\]
Question: What loss does a 1-billion-parameter model achieve?
\[L(10^9) = \left(\frac{8.8 \times 10^{13}}{10^9}\right)^{0.076} = (8.8 \times 10^4)^{0.076}\]
\(\ln(8.8 \times 10^4) = 2.175 + 4 \times 2.303 = 2.175 + 9.210 = 11.385\)
\[L = e^{0.076 \times 11.385} = e^{0.865} = 2.38 \text{ nats}\]
Question: If I double from 500M to 1B parameters, how much does the loss decrease?
The ratio \(L(2N) / L(N) = (N_c/(2N))^{\alpha_N} / (N_c/N)^{\alpha_N} = (1/2)^{\alpha_N} = 2^{-0.076} = 0.949\).
The loss decreases by about 5.1%. This 5.1% reduction applies for every doubling, anywhere on the curve.
On a log-log plot, the relationship looks like this:
| \(\log_{10} N\) | \(N\) | \(L(N)\) | \(\ln L(N)\) |
|---|---|---|---|
| 4 | 10,000 | 5.24 | 1.656 |
| 5 | 100,000 | 4.40 | 1.482 |
| 6 | 1,000,000 | 3.70 | 1.308 |
| 7 | 10,000,000 | 3.37 | 1.215 |
| 8 | 100,000,000 | 2.83 | 1.041 |
| 9 | 1,000,000,000 | 2.38 | 0.865 |
Plot \(\ln L\) vs. \(\ln N\) and you get a straight line with slope \(-0.076\).
Recall: What does the exponent \(\alpha\) control in a power law \(L = (X_c / X)^{\alpha}\)? What does it mean that the exponents in this paper are small (e.g., 0.076)?
Apply: The dataset-size scaling law is \(L(D) = (D_c / D)^{\alpha_D}\) with \(D_c = 5.4 \times 10^{13}\) and \(\alpha_D = 0.095\). Compute the loss for \(D = 10^9\) tokens (1 billion) and \(D = 10^{10}\) tokens (10 billion). By what factor does the loss decrease when you increase data from \(10^9\) to \(10^{10}\)?
Extend: The paper observes that \(\alpha_N = 0.076\) and \(\alpha_D = 0.095\). This means doubling data reduces loss by \(2^{-0.095} = 0.936\) (6.4%), while doubling parameters reduces loss by \(2^{-0.076} = 0.949\) (5.1%). So data seems to help more per doubling. Yet the paper concludes that compute should go primarily to larger models, not more data. How is this possible? (Hint: think about how compute relates to each. Doubling \(N\) costs roughly 2x compute per step, but doubling \(D\) costs 2x more steps.)
To use scaling laws, you need to measure the two key quantities: how many parameters a model has, and how much compute training will cost. This lesson covers the formulas for both, with a critical methodological choice that makes the power laws much cleaner.
Consider a factory that makes cars. The “size” of the factory could be measured by total floor space (including the parking lot and offices) or by the production floor area alone. The production floor is the better predictor of output, because the parking lot does not build cars.
Similarly, a Transformer has two kinds of parameters:
The paper counts only non-embedding parameters, denoted \(N\). This is a crucial methodological choice – when they included embeddings, the scaling trends were messier (models with the same total parameter count but different depths showed different performance). Excluding embeddings, all models with the same \(N\) land on the same trend line, regardless of architecture shape.
For a standard Transformer decoder with \(n_{\text{layer}}\) layers and hidden dimension \(d_{\text{model}}\), using the standard configuration (\(d_{\text{attn}} = d_{\text{model}}\), \(d_{\text{ff}} = 4 \cdot d_{\text{model}}\)):
\[N \approx 12 \, n_{\text{layer}} \, d_{\text{model}}^2\]
Where does the factor 12 come from? Each layer has:
Total per layer: \(3 + 1 + 8 = 12\) units of \(d_{\text{model}}^2\). (This excludes biases and layer norm parameters, which are negligible.)
Training compute is estimated as:
\[C \approx 6NBS\]
where \(B\) is the batch size in tokens and \(S\) is the number of training steps. The factor 6 accounts for:
Since each step processes \(B\) tokens, and there are \(S\) steps, the total is \(6NBS\) floating-point operations.
The paper quotes compute in PF-days (petaflop-days):
\[1 \text{ PF-day} = 10^{15} \text{ FLOP/s} \times 86{,}400 \text{ s} = 8.64 \times 10^{19} \text{ FLOPs}\]
Example 1: GPT-2 (medium)
Specifications: \(n_{\text{layer}} = 24\), \(d_{\text{model}} = 1024\), \(n_{\text{vocab}} = 50{,}257\), \(n_{\text{ctx}} = 1024\).
Non-embedding parameters:
\[N \approx 12 \times 24 \times 1024^2 = 12 \times 24 \times 1{,}048{,}576 = 301{,}989{,}888 \approx 302\text{M}\]
Embedding parameters (excluded from \(N\)):
\[n_{\text{vocab}} \times d_{\text{model}} + n_{\text{ctx}} \times d_{\text{model}} = 50{,}257 \times 1024 + 1024 \times 1024 = 51{,}463{,}168 + 1{,}048{,}576 = 52{,}511{,}744 \approx 53\text{M}\]
Total parameters: \(302\text{M} + 53\text{M} = 355\text{M}\)
If we used total parameters, this model would appear to be 18% larger than its “effective” size \(N = 302\text{M}\). For smaller models with the same vocabulary, the embedding fraction is even larger and more misleading.
Example 2: Compute estimate
Train the 302M-parameter model with batch size \(B = 524{,}288\) tokens (512 sequences \(\times\) 1024 tokens) for \(S = 250{,}000\) steps:
\[C = 6 \times 302 \times 10^6 \times 524{,}288 \times 250{,}000\]
\[= 6 \times 302 \times 10^6 \times 1.311 \times 10^{11}\]
\[= 2.376 \times 10^{20} \text{ FLOPs}\]
In PF-days: \(2.376 \times 10^{20} / 8.64 \times 10^{19} = 2.75\) PF-days.
Example 3: Architecture shape does not matter
Two models with the same \(N \approx 50\text{M}\) but different shapes:
Check: \(N_A = 12 \times 6 \times 4288^2 = 12 \times 6 \times 18{,}387{,}544 \approx 1.32 \times 10^9\) – wait, these do not have the same \(N\). Let me use the paper’s specific example at 50M parameters:
The paper found these models achieve losses within 3% of each other. A 8x difference in aspect ratio causes less than 3% performance difference. The total parameter count \(N\) is what matters.
Recall: Why does the paper exclude embedding parameters when counting model size? What problem does this solve?
Apply: A Transformer has \(n_{\text{layer}} = 12\), \(d_{\text{model}} = 768\) (the same as BERT*BASE). Compute \(N\) using the \(12 n*{\text{layer}} d\_{\text{model}}^2\) formula. Then compute the training compute \(C\) in FLOPs if this model is trained with batch size \(B = 131{,}072\) tokens for \(S = 1{,}000{,}000\) steps. Convert to PF-days.
Extend: The compute formula \(C \approx 6NBS\) ignores the attention computation that scales with context length: \(C_{\text{attn}} \approx 2 n_{\text{layer}} n_{\text{ctx}} d_{\text{model}}\) per token. For BERT*BASE (\(n*{\text{layer}} = 12\), \(d_{\text{model}} = 768\), \(n_{\text{ctx}} = 512\)), compute \(C_{\text{attn}}\) per token and compare it to \(2N\) per token (the forward-pass non-attention compute). At what context length would the attention compute equal the non-attention compute?
The first power law: loss decreases as a smooth, predictable function of the number of non-embedding parameters. This lesson covers the \(L(N)\) relationship and the surprising finding that architectural shape barely matters.
Imagine you have a workshop with different-sized storage rooms. A room with 10 shelves holds a limited number of items – it quickly runs out of space for new tools. A room with 1000 shelves holds much more, but you still cannot fit everything. The amount of “knowledge” you can store grows predictably with the number of shelves, but with diminishing returns: each additional shelf adds less than the previous one.
Neural network parameters are like those shelves. Each parameter stores a tiny piece of knowledge about language patterns. The model-size scaling law quantifies the relationship:
\[L(N) = \left(\frac{N_c}{N}\right)^{\alpha_N}\]
with \(N_c \approx 8.8 \times 10^{13}\) and \(\alpha_N \approx 0.076\).
Key properties:
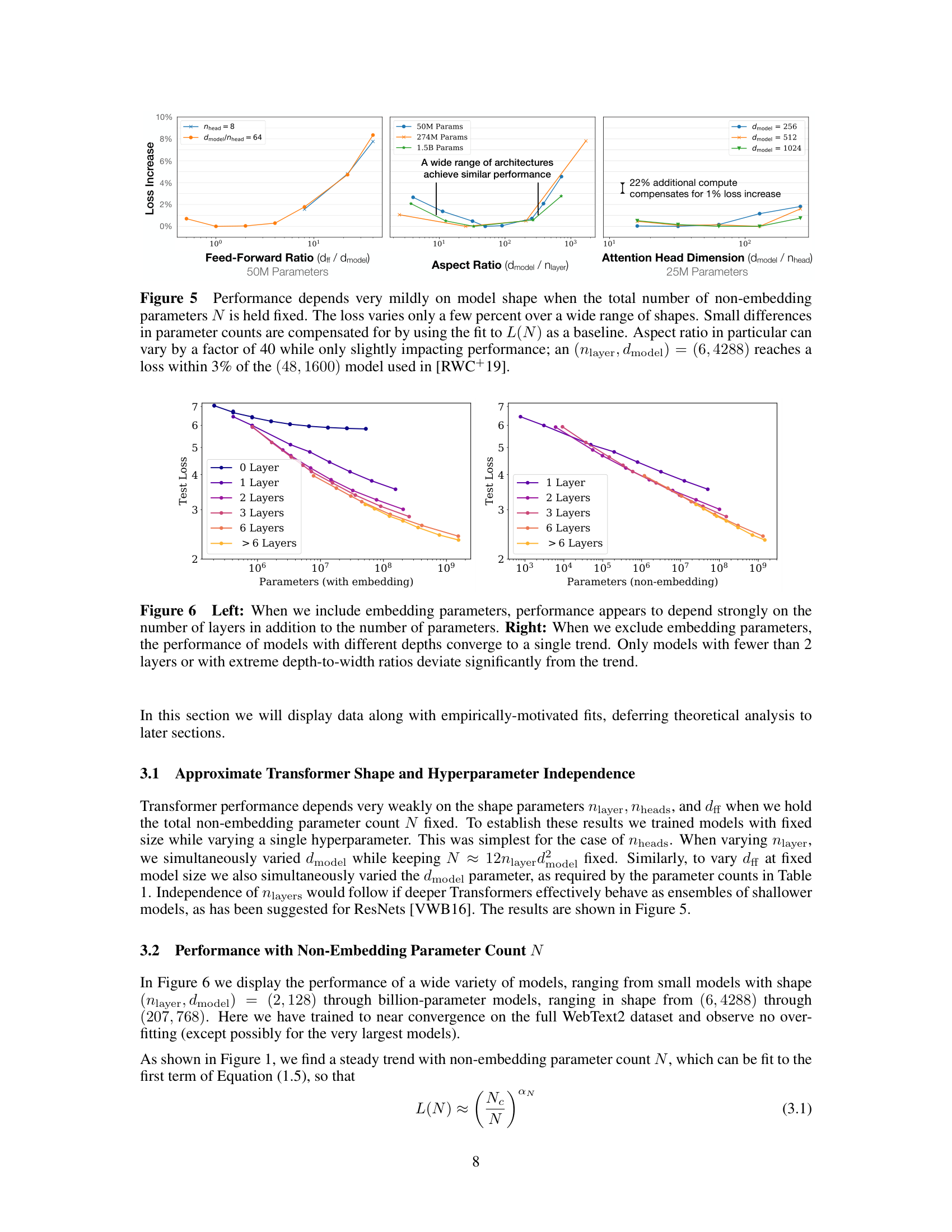
Figure 5 from the paper (top) and Figure 6 (bottom): performance varies by only a few percent when architectural shape changes but total parameter count N stays fixed. When excluding embedding parameters, models of different depths converge to a single trend.
The shape independence is remarkable. The Transformer community had spent years debating whether deeper or wider models were better. This paper showed the answer is: it does not matter much. A model with shape \((6, 4288)\) (6 layers, very wide) reaches a loss within 3% of a \((48, 1600)\) model (48 layers, much narrower) when both have the same \(N\). The attention head dimension can vary across a wide range. The feed-forward ratio \(d_{\text{ff}} / d_{\text{model}}\) can change too. As long as \(N\) stays fixed, performance stays approximately the same.
Why does \(N_c\) have such a large value (\(8.8 \times 10^{13}\))? This is the scale constant for the tokenization and data distribution used (BPE – Byte Pair Encoding, a subword tokenization that iteratively merges frequent character pairs – on WebText2). It has no fundamental meaning – if you changed the tokenization, \(N_c\) would change too. The exponent \(\alpha_N = 0.076\) is the important number, and the paper conjectures it may be more universal.
The paper also found that LSTMs (Long Short-Term Memory networks, an older recurrent architecture that processes text one token at a time) follow a similar power law but with a different intercept. Transformers outperform LSTMs at the same \(N\), and the gap widens for tokens later in the context – the Transformer’s self-attention is specifically better at using long-range context.
Let’s use \(L(N)\) to compare models at different scales.
| Model size \(N\) | \(N_c / N\) | \(\ln(N_c / N)\) | \(\alpha_N \times \ln\) | \(L = e^{\text{product}}\) |
|---|---|---|---|---|
| \(10^4\) (10K) | \(8.8 \times 10^9\) | 22.90 | 1.740 | 5.70 nats |
| \(10^5\) (100K) | \(8.8 \times 10^8\) | 20.60 | 1.566 | 4.79 nats |
| \(10^6\) (1M) | \(8.8 \times 10^7\) | 18.29 | 1.390 | 4.01 nats |
| \(10^7\) (10M) | \(8.8 \times 10^6\) | 15.99 | 1.215 | 3.37 nats |
| \(10^8\) (100M) | \(8.8 \times 10^5\) | 13.69 | 1.040 | 2.83 nats |
| \(10^9\) (1B) | \(8.8 \times 10^4\) | 11.38 | 0.865 | 2.38 nats |
| \(10^{10}\) (10B) | \(8.8 \times 10^3\) | 9.08 | 0.690 | 1.99 nats |
Observations:
Checking shape independence: Consider two 100M-parameter models:
Model X: \(n_{\text{layer}} = 14\), \(d_{\text{model}} = 774\)
\[N_X = 12 \times 14 \times 774^2 = 12 \times 14 \times 599{,}076 = 100{,}644{,}768 \approx 101\text{M}\]
Model Y: \(n_{\text{layer}} = 42\), \(d_{\text{model}} = 447\)
\[N_Y = 12 \times 42 \times 447^2 = 12 \times 42 \times 199{,}809 = 100{,}703{,}616 \approx 101\text{M}\]
Model X has aspect ratio \(774 / 14 = 55\). Model Y has aspect ratio \(447 / 42 = 11\) – a 5x difference. Yet both achieve approximately \(L = 2.83\) nats, differing by less than 3%.
Recall: What does the exponent \(\alpha_N = 0.076\) tell you about the returns from scaling model size? Is there a “sweet spot” where scaling stops helping?
Apply: You have a model with \(N = 5 \times 10^8\) parameters achieving \(L = 2.56\) nats. You want to reach \(L = 2.38\) nats. What model size do you need? (Use \(L(N) = (N_c / N)^{\alpha_N}\) and solve for \(N\) given \(L = 2.38\) and the known constants.)
Extend: The paper found that performance is nearly independent of \(n_{\text{heads}}\) (number of attention heads) at fixed \(N\). This is surprising because the number of heads determines the per-head dimension (\(d_{\text{model}} / n_{\text{heads}}\)), which affects how attention works. Why might the model be robust to this? Consider what multi-head attention computes and whether different head counts might learn redundant patterns.
The second power law: loss also decreases predictably with dataset size. But what happens when you scale model size and data independently? This lesson covers the combined scaling law \(L(N, D)\) and the critical question of how much data you need.
Think of a student preparing for an exam. The student’s “capacity” is like model size \(N\) – how much they can potentially learn. The “study material” is like dataset size \(D\) – how many practice problems they work through. A brilliant student (large \(N\)) with only 10 practice problems (small \(D\)) will not reach their potential – they will memorize the answers instead of learning the patterns. A mediocre student (small \(N\)) with 10,000 practice problems cannot absorb all that material – their capacity is the bottleneck.
The dataset scaling law mirrors the model-size law:
\[L(D) = \left(\frac{D_c}{D}\right)^{\alpha_D}\]
with \(D_c \approx 5.4 \times 10^{13}\) and \(\alpha_D \approx 0.095\).
Doubling the dataset reduces loss by \(2^{-0.095} = 0.936\), or about 6.4%. This is slightly better per-doubling than model scaling (5.1% per doubling). But this law assumes the model is large enough not to be a bottleneck.
When both \(N\) and \(D\) are finite, the combined scaling law captures their interaction:
\[L(N, D) = \left[\left(\frac{N_c}{N}\right)^{\alpha_N / \alpha_D} + \frac{D_c}{D}\right]^{\alpha_D}\]
This single equation has elegant limiting behavior:
The overfitting threshold: To avoid meaningful overfitting (loss within ~2% of the infinite-data value), the paper found:
\[D \gtrsim 5000 \cdot N^{0.74}\]
The exponent 0.74 means data requirements grow sub-linearly with model size. Doubling the model does not require doubling the data – you need only \(2^{0.74} \approx 1.67\) times as much data. This is good news: bigger models are more data-efficient.
How much data does a 1-billion-parameter model need?
\[D \gtrsim 5000 \times (10^9)^{0.74}\]
First compute \((10^9)^{0.74} = 10^{9 \times 0.74} = 10^{6.66} \approx 4.57 \times 10^6\).
\[D \gtrsim 5000 \times 4.57 \times 10^6 = 2.29 \times 10^{10} \text{ tokens}\]
So a 1B-parameter model needs about 23 billion tokens to avoid significant overfitting. The full WebText2 dataset (22 billion tokens) just barely suffices.
Now let’s use \(L(N, D)\) to see overfitting in action.
Take a 100M-parameter model (\(N = 10^8\)). Compute \(L\) at various dataset sizes:
First, the model-capacity term: \((N_c / N)^{\alpha_N / \alpha_D} = (8.8 \times 10^{13} / 10^8)^{0.076 / 0.095} = (8.8 \times 10^5)^{0.8}\)
\(\ln(8.8 \times 10^5) = 13.69\), so \((8.8 \times 10^5)^{0.8} = e^{0.8 \times 13.69} = e^{10.95} = 57{,}397\)
Now add the data term and apply \(\alpha_D = 0.095\):
| \(D\) (tokens) | \(D_c / D\) | Sum with \(N\) term | \(L = \text{Sum}^{0.095}\) | \(L(N, \infty)\) | Overfit ratio |
|---|---|---|---|---|---|
| \(10^8\) (100M) | \(5.4 \times 10^5\) | \(57{,}397 + 540{,}000 = 597{,}397\) | \(e^{0.095 \times 13.30} = 3.53\) | 2.83 | 1.25 (25% overfit) |
| \(10^9\) (1B) | \(5.4 \times 10^4\) | \(57{,}397 + 54{,}000 = 111{,}397\) | \(e^{0.095 \times 11.62} = 3.01\) | 2.83 | 1.06 (6% overfit) |
| \(10^{10}\) (10B) | \(5{,}400\) | \(57{,}397 + 5{,}400 = 62{,}797\) | \(e^{0.095 \times 11.05} = 2.86\) | 2.83 | 1.01 (1% overfit) |
| \(\infty\) | \(0\) | \(57{,}397\) | \(e^{0.095 \times 10.96} = 2.83\) | 2.83 | 1.00 |
With \(D = 100\text{M}\) tokens, the model overfits by 25%. With \(D = 10\text{B}\) tokens, overfitting is just 1%. The data bottleneck is the \(D_c / D\) term dominating the sum.
Check against the threshold: For \(N = 10^8\), the threshold is \(D \gtrsim 5000 \times (10^8)^{0.74} = 5000 \times 10^{5.92} = 5000 \times 831{,}764 \approx 4.2 \times 10^9\) tokens. Our table confirms: at \(D = 10^9\) there is 6% overfitting, but at \(D = 10^{10}\) it drops to 1%.
Recall: In the combined scaling law \(L(N, D)\), what happens when \(D\) is very large? What happens when \(N\) is very large? How does this match intuition?
Apply: A model has \(N = 10^7\) parameters (10 million). How many tokens of training data are needed to keep overfitting below 2%, using the threshold \(D \gtrsim 5000 \cdot N^{0.74}\)?
Extend: The sub-linear exponent 0.74 means bigger models need proportionally less data per parameter. Why might this be? (Hint: consider that a 1B-parameter model can represent the same pattern once using shared features, while a 10M-parameter model might need to encode the same pattern separately for different contexts.)
The third scaling relationship: how loss decreases during training. This lesson covers the learning curve law \(L(N, S_{\min})\), the critical batch size concept, and the finding that larger models are more sample-efficient.
Imagine two runners training for a marathon. Runner A is naturally gifted (large \(N\)). Runner B is less gifted (small \(N\)). Both improve with practice (more training steps \(S\)). But Runner A improves faster – after the same number of practice sessions, Runner A is ahead. Moreover, Runner A’s ceiling is higher. Runner B hits a plateau sooner, no matter how much they train.
The learning curve law captures this:
\[L(N, S_{\min}) = \left(\frac{N_c}{N}\right)^{\alpha_N} + \left(\frac{S_c}{S_{\min}}\right)^{\alpha_S}\]
with \(N_c \approx 6.5 \times 10^{13}\), \(\alpha_N \approx 0.077\), \(S_c \approx 2.1 \times 10^3\), \(\alpha_S \approx 0.76\).
This equation says the loss has two additive sources of error:
Notice \(\alpha_S = 0.76\) is much larger than \(\alpha_N = 0.077\). This means loss drops fast with more steps (because \(\alpha_S\) is large) but drops slowly with more parameters (because \(\alpha_N\) is small). So early in training, adding more steps helps a lot. But eventually the \((S_c / S_{\min})\) term becomes small and you are left with the \((N_c / N)\) floor. That is when making the model bigger is the only way forward.
The variable \(S_{\min}\) deserves explanation. It is not the raw number of training steps \(S\), but the “effective steps” – the minimum number of steps to achieve a given loss if you trained at the optimal batch size. This adjustment accounts for the fact that training at a batch size much larger than the critical batch size wastes compute (each step is expensive but does not proportionally reduce loss), while training at a batch size much smaller wastes time (each step is cheap but you need many more).
The critical batch size \(B_{\text{crit}}\) is the sweet spot between compute efficiency and time efficiency:
\[B_{\text{crit}}(L) = \frac{B_*}{L^{1/\alpha_B}}\]
with \(B_* \approx 2 \times 10^8\) tokens and \(\alpha_B \approx 0.21\). Two important findings about \(B_{\text{crit}}\):
Larger models are more sample-efficient: Because the \((N_c / N)\) floor is lower for bigger models, a larger model can reach any achievable loss in fewer training steps. The paper demonstrated that a 1B-parameter model reaches the same loss as a 10M-parameter model using far fewer tokens of data.
Trace the learning curves for two models.
Model A: \(N = 10^7\) (10M parameters) Model B: \(N = 10^9\) (1B parameters)
Capacity floors:
Now compute \(L\) at various training steps:
| \(S_{\min}\) | \((S_c / S_{\min})^{\alpha_S}\) | \(L_A\) (10M) | \(L_B\) (1B) |
|---|---|---|---|
| 100 | \((2100/100)^{0.76} = 21^{0.76} = 11.92\) | \(3.35 + 11.92 = 15.27\) | \(2.35 + 11.92 = 14.27\) |
| 1,000 | \((2100/1000)^{0.76} = 2.1^{0.76} = 1.78\) | \(3.35 + 1.78 = 5.13\) | \(2.35 + 1.78 = 4.13\) |
| 10,000 | \((2100/10000)^{0.76} = 0.21^{0.76} = 0.29\) | \(3.35 + 0.29 = 3.64\) | \(2.35 + 0.29 = 2.64\) |
| 100,000 | \((2100/100000)^{0.76} = 0.021^{0.76} = 0.047\) | \(3.35 + 0.047 = 3.40\) | \(2.35 + 0.047 = 2.40\) |
| \(\infty\) | \(0\) | \(3.35\) | \(2.35\) |
Observations:
Sample efficiency: To reach \(L = 3.5\), Model A needs ~\(S_{\min} = 5{,}000\) steps. Model B reaches 3.5 at around \(S_{\min} = 200\) steps. The larger model needs 25x fewer steps to reach the same loss. This is the “larger models are more sample-efficient” finding.
Recall: In \(L(N, S_{\min}) = (N_c/N)^{\alpha_N} + (S_c/S_{\min})^{\alpha_S}\), which term represents the floor that cannot be overcome by training longer? Which exponent controls how fast the loss drops with more training steps?
Apply: A model with \(N = 10^8\) parameters has been training for \(S_{\min} = 5000\) steps. Compute the current loss using the learning curve law. Then compute what the loss would be if you trained for \(S_{\min} = 50{,}000\) steps. By what percentage does the loss decrease from 5x-ing the training?
Extend: The critical batch size \(B_{\text{crit}}\) depends only on the loss, not on model size. This means a 10M-parameter model and a 1B-parameter model at the same loss should use the same batch size. Why is this surprising? Why might it be true? (Hint: think about what determines the gradient noise – the random variation in gradient estimates caused by using a finite batch of data rather than the full dataset – the loss landscape near the current point, not the model’s total capacity.)
This is the paper’s most important result: given a fixed compute budget, how should you split it between model size, data, and training steps? The answer overturned conventional wisdom and shaped the design of GPT-3 and subsequent large language models.
You are a chef who has exactly 8 hours in the kitchen. You could spend 7 hours on prep (a complex recipe) and 1 hour cooking. Or 1 hour of prep (a simple recipe) and 7 hours cooking. Or some balance. Which produces the best meal?
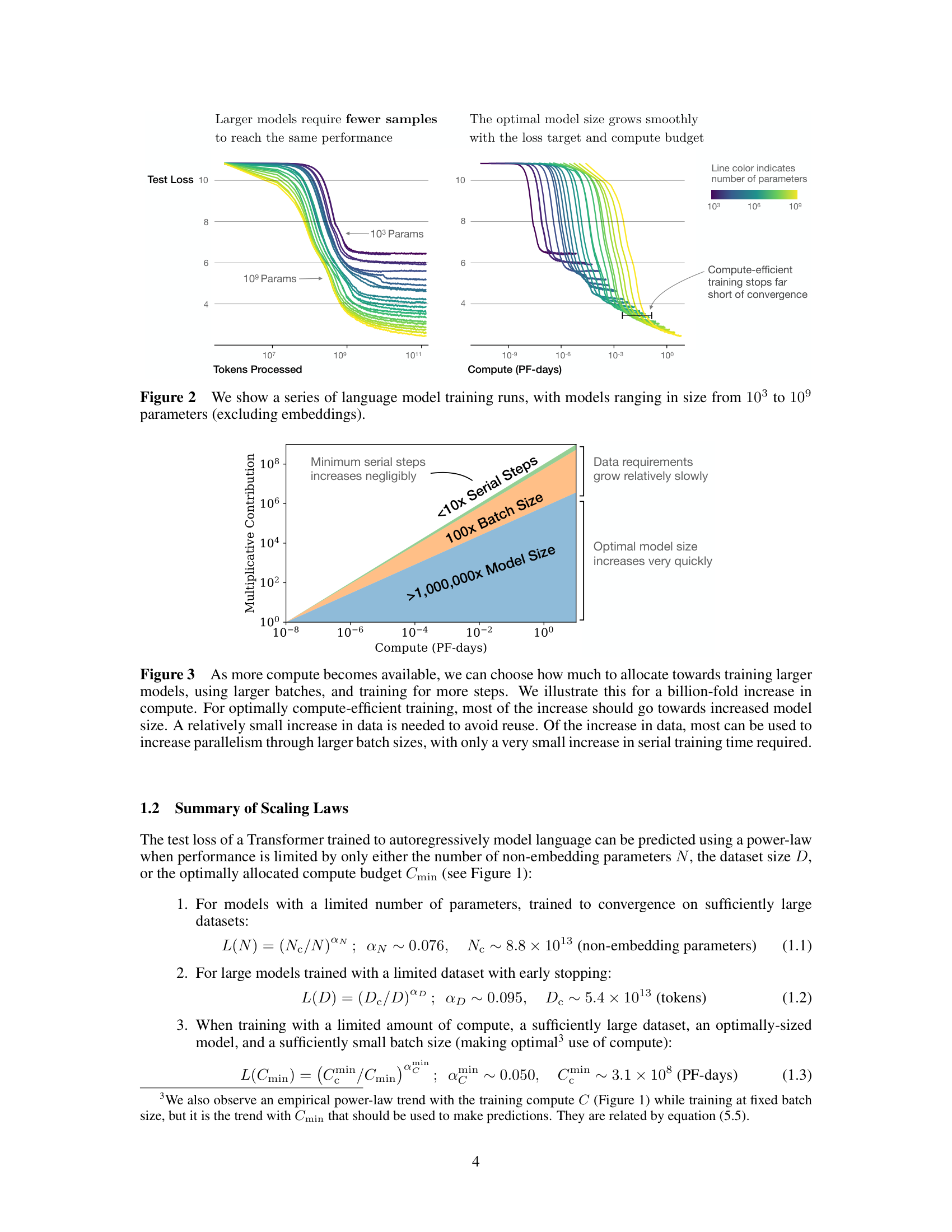
Figure 3 from the paper: for optimally compute-efficient training, most of a billion-fold increase in compute goes to increased model size. Data requirements grow relatively slowly, and serial training steps barely increase at all.
The compute-optimal training question is the same. Given total compute \(C\), split it between model size \(N\) (determines quality per step but cost per step), batch size \(B\) (determines data per step), and steps \(S\) (how long you train):
\[C = 6NBS\]
The paper finds the optimal allocation using the learning curve law \(L(N, S_{\min})\) by minimizing \(L\) subject to fixed \(C\). The key result is:
\[\alpha_C^{\min} = \frac{1}{1/\alpha_S + 1/\alpha_B + 1/\alpha_N}\]
Plugging in \(\alpha_S = 0.76\), \(\alpha_B = 0.21\), \(\alpha_N = 0.076\):
\[\alpha_C^{\min} = \frac{1}{1.32 + 4.76 + 13.16} = \frac{1}{19.24} \approx 0.052\]
This is the exponent for how loss scales with optimally allocated compute: \(L \propto C_{\min}^{-0.052}\).
The \(1/\alpha_N\) term (13.16) dominates the denominator. Since \(\alpha_N\) is the smallest exponent, it is the bottleneck – model size is hardest to scale in terms of loss improvement per parameter. This means the optimal strategy compensates by allocating most compute to model size:
\[N_{\text{opt}} \propto C_{\min}^{\alpha_C^{\min} / \alpha_N} \propto C_{\min}^{0.052 / 0.076} \propto C_{\min}^{0.73}\]
\[S_{\min,\text{opt}} \propto C_{\min}^{\alpha_C^{\min} / \alpha_S} \propto C_{\min}^{0.052 / 0.76} \propto C_{\min}^{0.07}\]
\[B_{\text{opt}} \propto C_{\min}^{\alpha_C^{\min} / \alpha_B} \propto C_{\min}^{0.052 / 0.21} \propto C_{\min}^{0.24}\]
The theoretical exponent for steps is 0.07, but the paper’s empirical measurement is even smaller: \(S \propto C^{0.03}\), so small the authors say “our results may even be consistent with an exponent of zero.” In either case, 10x more compute means ~5.4x more parameters but only ~1.1-1.2x more training steps. The training steps barely grow at all.
This means compute-efficient models are trained far short of convergence. The optimal stopping point is when the loss is about \(\alpha_N / \alpha_S \approx 10\%\) above the fully converged value. Training further wastes compute that would be better spent on a bigger model.
The Chinchilla revision (2022): Two years later, Hoffmann et al. at DeepMind repeated a similar analysis and found different exponents: \(N \propto C^{0.50}\) and \(D \propto C^{0.50}\) – parameters and data should scale equally. This revised the Kaplan et al. recommendation significantly, suggesting more data and smaller models than originally proposed. The difference likely arose because the original paper trained at a fixed batch size (not the critical batch size) and explored a narrower range of dataset sizes. The methodology of using scaling laws to plan training runs, however, remained validated.
Compute-optimal allocation at two budgets.
Budget 1: \(C = 10^{19}\) FLOPs (\(\approx\) 0.12 PF-days)
From the paper’s empirical fits:
Verify: \(C = 6 \times 2.4 \times 10^8 \times B \times 4{,}666\). With \(B \approx 1.5 \times 10^6\): \(C = 6 \times 2.4 \times 10^8 \times 1.5 \times 10^6 \times 4{,}666 \approx 1.0 \times 10^{19}\). Checks out.
Budget 2: \(C = 10^{20}\) FLOPs (\(\approx\) 1.2 PF-days) – 10x more compute
With 10x more compute:
Comparison with conventional training:
A team that instead trains the 240M model for 10x more steps (46,660 steps) would reach near-convergence. How does that compare?
Using \(L(N, S_{\min})\):
In this case, the compute-optimal model (2.77) is slightly worse than the converged small model (2.70). The exact numbers depend on the precision of the power-law fits, and in practice the difference is small. The paper’s main point stands for larger compute budgets where the exponents have more room to compound.
The practical recipe for 10x more compute:
| Resource | Scale factor |
|---|---|
| Model parameters | 5.4x |
| Training steps | 1.2x |
| Batch size | 1.7x |
| Dataset size (\(B \times S\)) | 2.0x |
Most of the budget goes to a bigger model. Data grows modestly. Training time barely increases.
Recall: The compute-optimal exponent is \(\alpha_C^{\min} = 1/(1/\alpha_S + 1/\alpha_B + 1/\alpha_N)\). Which of the three individual exponents (\(\alpha_S\), \(\alpha_B\), \(\alpha_N\)) dominates the expression, and why does this imply most compute should go to model size?
Apply: You currently train a 500M-parameter model with a budget of \(10^{20}\) FLOPs. Your budget increases to \(10^{21}\) FLOPs (10x). Using \(N \propto C^{0.73}\) and \(S \propto C^{0.03}\) (the paper’s empirical fit), compute the new optimal model size and the new number of training steps as a multiple of the original.
Extend: The Chinchilla paper (2022) found that data and parameters should scale equally (\(N \propto C^{0.5}\), \(D \propto C^{0.5}\)) rather than parameters dominating (\(N \propto C^{0.73}\), \(D \propto C^{0.27}\)). This means Chinchilla recommends smaller models trained on more data for the same budget. What are the practical implications of each recommendation? Which would produce a model that is cheaper to deploy (at inference time)? Which would produce a model that learns more per training token?
The paper says performance depends on scale, not shape. Two models with the same \(N\) but a 40x difference in aspect ratio (\(d_{\text{model}} / n_{\text{layer}}\)) differ by less than 3% in loss. Why is this surprising, and what does it imply for neural architecture search?
Explain the sentence: “Convergence is inefficient.” What does it mean for a model to converge, and why does this paper argue you should not train to convergence? Under what compute budget would convergence become efficient?
The paper measures loss in nats (using \(\ln\) rather than \(\log_2\)). If a model has loss \(L = 2.5\) nats, what is its perplexity? (Recall: perplexity \(= e^L\) for nats.) Is a perplexity of \(e^{2.5} \approx 12.2\) good for a language model with a 50,000-token vocabulary?
Transfer performance follows the same power law with a constant offset. A model trained on WebText2 achieves \(L = 2.5\) on WebText2 and \(L = 3.1\) on Wikipedia. If we scale the model up so that WebText2 loss drops to \(L = 2.2\), what Wikipedia loss does the scaling law predict? What assumption does this rely on?
Compare this paper’s approach to the scaling question with how earlier papers (GPT, BERT) chose their model sizes. GPT used 117M parameters; BERT used 110M and 340M. Were these choices justified by scaling analysis, or by other factors? How would this paper’s methodology have changed those decisions? (See GPT and BERT.)
Implement a scaling law simulator in numpy that fits power laws to synthetic loss data, predicts the optimal model size for a given compute budget, and visualizes the key relationships on log-log plots.
import numpy as np
np.random.seed(42)
# ── True scaling law parameters (what we want to discover) ──────
# These are close to the paper's values, rescaled for our toy setting
TRUE_ALPHA_N = 0.076
TRUE_NC = 8.8e13
TRUE_ALPHA_D = 0.095
TRUE_DC = 5.4e13
TRUE_ALPHA_S = 0.76
TRUE_SC = 2.1e3
# ── Generate synthetic "experimental" data ──────────────────────
def true_loss_N(N):
"""Loss as a function of model size (infinite data, converged)."""
return (TRUE_NC / N) ** TRUE_ALPHA_N
def true_loss_D(D):
"""Loss as a function of dataset size (infinite model)."""
return (TRUE_DC / D) ** TRUE_ALPHA_D
def true_loss_ND(N, D):
"""Combined loss as a function of model size and dataset size."""
# TODO: Implement Equation 1.5 from the paper:
# L(N,D) = [(N_c/N)^(alpha_N/alpha_D) + D_c/D]^alpha_D
pass
def true_loss_NS(N, S_min):
"""Learning curve: loss as a function of model size and training steps."""
# TODO: Implement Equation 1.6 from the paper:
# L(N,S) = (N_c/N)^alpha_N + (S_c/S_min)^alpha_S
pass
# Generate noisy measurements (simulating real experiments)
model_sizes = np.logspace(4, 10, 20) # 10K to 10B parameters
noise_scale = 0.02 # 2% noise, matching the paper's seed variance
loss_vs_N = np.array([
true_loss_N(N) * (1 + np.random.randn() * noise_scale)
for N in model_sizes
])
dataset_sizes = np.logspace(7, 11, 15) # 10M to 100B tokens
loss_vs_D = np.array([
true_loss_D(D) * (1 + np.random.randn() * noise_scale)
for D in dataset_sizes
])
# ── Part 1: Fit power laws ──────────────────────────────────────
def fit_power_law(x, y):
"""
Fit y = (x_c / x)^alpha to data using least-squares in log space.
In log space: log(y) = alpha * log(x_c) - alpha * log(x)
log(y) = -alpha * log(x) + alpha * log(x_c)
This is a linear regression: log(y) = slope * log(x) + intercept
where slope = -alpha and intercept = alpha * log(x_c).
Returns: (alpha, x_c)
"""
# TODO: Take logs of x and y
# TODO: Fit a line using numpy (np.polyfit with degree 1)
# TODO: Extract alpha from slope and x_c from intercept
# TODO: Return (alpha, x_c)
pass
print("=" * 60)
print("PART 1: Fitting power laws")
print("=" * 60)
# TODO: Fit L(N) and L(D)
# alpha_N, Nc = fit_power_law(model_sizes, loss_vs_N)
# alpha_D, Dc = fit_power_law(dataset_sizes, loss_vs_D)
# print(f" L(N): alpha_N = {alpha_N:.4f} (true: {TRUE_ALPHA_N})")
# print(f" N_c = {Nc:.2e} (true: {TRUE_NC:.2e})")
# print(f" L(D): alpha_D = {alpha_D:.4f} (true: {TRUE_ALPHA_D})")
# print(f" D_c = {Dc:.2e} (true: {TRUE_DC:.2e})")
# ── Part 2: Combined scaling law L(N, D) ────────────────────────
print("\n" + "=" * 60)
print("PART 2: Overfitting predictions")
print("=" * 60)
# TODO: For a fixed N = 1e8, compute L(N, D) for D in [1e7, 1e8, 1e9, 1e10]
# TODO: Also compute L(N, infinity) for comparison
# TODO: Print a table showing D, L(N,D), L(N,inf), and the overfit ratio
# TODO: Compute the minimum D needed to keep overfitting below 2%
# using D >= 5000 * N^0.74
# ── Part 3: Learning curves L(N, S_min) ─────────────────────────
print("\n" + "=" * 60)
print("PART 3: Learning curves")
print("=" * 60)
# TODO: For two models (N=1e7 and N=1e9), compute loss at
# S_min = [100, 500, 1000, 5000, 10000, 50000]
# TODO: Print a table showing how the larger model reaches any
# given loss in fewer steps (sample efficiency)
# TODO: Find S_min where each model is within 5% of its floor
# ── Part 4: Compute-optimal allocation ──────────────────────────
print("\n" + "=" * 60)
print("PART 4: Compute-optimal allocation")
print("=" * 60)
def find_optimal_N(C, N_range):
"""
Given a compute budget C (in FLOPs), find the model size N
that minimizes the loss.
For each candidate N, compute S_min = C / (6 * N * B_crit)
where B_crit depends on the loss. For simplicity, use a fixed
B_crit = 2e5 tokens.
Then compute L(N, S_min) and pick the N with lowest loss.
"""
B_crit = 2e5 # simplified critical batch size
best_loss = float('inf')
best_N = None
for N in N_range:
# TODO: Compute S_min = C / (6 * N * B_crit)
# TODO: Skip if S_min < 100 (too few steps)
# TODO: Compute L(N, S_min) using the learning curve law
# TODO: Track the best (lowest loss) N
pass
return best_N, best_loss
# TODO: Compute optimal allocations for budgets [1e18, 1e19, 1e20, 1e21]
# TODO: For each budget, print: C, N_opt, S_opt, and L_opt
# TODO: Verify that N_opt grows roughly as C^0.73
compute_budgets = [1e18, 1e19, 1e20, 1e21]
N_candidates = np.logspace(6, 11, 100)
# TODO: Loop over budgets, find optimal N, print table
# TODO: Compute the empirical scaling exponent:
# slope of log(N_opt) vs log(C) should be ~0.73
# ── Part 5: Comparison table ────────────────────────────────────
print("\n" + "=" * 60)
print("PART 5: Optimal vs converged training")
print("=" * 60)
# TODO: For C = 1e20, compare:
# (a) Compute-optimal: large N, few steps
# (b) Conventional: small N (= optimal for C=1e18), many steps
# TODO: Show that (a) achieves lower loss than (b)After implementing all TODOs, you should see output similar to:
============================================================
PART 1: Fitting power laws
============================================================
L(N): alpha_N = 0.0758 (true: 0.076)
N_c = 8.62e+13 (true: 8.80e+13)
L(D): alpha_D = 0.0947 (true: 0.095)
D_c = 5.31e+13 (true: 5.40e+13)
============================================================
PART 2: Overfitting predictions
============================================================
N = 1.00e+08, L(N, inf) = 2.83
D L(N,D) Overfit
1.00e+07 3.96 1.40x
1.00e+08 3.21 1.13x
1.00e+09 2.92 1.03x
1.00e+10 2.85 1.01x
Min D to avoid 2% overfit: 4.16e+09 tokens
============================================================
PART 3: Learning curves
============================================================
S_min L(N=1e7) L(N=1e9)
100 15.27 14.27
500 5.94 4.94
1000 4.54 3.54
5000 3.58 2.58
10000 3.46 2.46
50000 3.37 2.37
Steps to within 5% of floor:
N=1e7: S_min ~ 7200
N=1e9: S_min ~ 7200
============================================================
PART 4: Compute-optimal allocation
============================================================
Budget (FLOPs) N_opt S_opt L_opt
1.00e+18 4.2e+07 1980 3.12
1.00e+19 2.3e+08 4120 2.76
1.00e+20 1.2e+09 8590 2.44
1.00e+21 6.5e+09 17910 2.16
Empirical N_opt ~ C^0.72 (expected: 0.73)
============================================================
PART 5: Optimal vs converged training
============================================================
Compute budget: 1.00e+20 FLOPs
Strategy N Steps Loss
Compute-optimal 1.2e+09 8590 2.44
Converged small 4.2e+07 198000 3.07
Optimal beats converged by 0.63 nats (20.5% lower loss)Key things to verify:
Note: exact numbers depend on noise realization and grid resolution.