
By the end of this course, you will be able to:
Before you can understand self-consistency, you need to understand the mechanism it exploits: the fact that a language model does not have to give the same answer every time. The way you extract text from a model – the decoding strategy – determines whether the output is fixed or variable.
Think about ordering coffee at a cafe. If you always order “the usual,” you get the same drink every time – that is greedy decoding. But if you tell the barista “surprise me with something I’d probably like,” you get a different drink each visit, weighted toward your known preferences – that is sampling. Both approaches use the same menu (the model’s probability distribution), but they produce different outputs.
An autoregressive language model generates text one token at a time. At each step, the model outputs a probability distribution over its entire vocabulary – every possible next word gets a probability. The decoding strategy decides how to pick the actual next token from this distribution.
Greedy decoding always picks the single most probable token at each step:
\[t_k = \arg\max_{t} P(t \mid t_1, t_2, \ldots, t_{k-1})\]
where:
Greedy decoding is deterministic: given the same input, the model always produces the same output. This means you get exactly one reasoning path per question.
Temperature sampling introduces controlled randomness. Before sampling, the model divides each log-probability by a temperature parameter \(T\):
\[P_T(t \mid t_1, \ldots, t_{k-1}) = \frac{\exp(\log P(t \mid t_1, \ldots, t_{k-1}) / T)}{\sum_{t'} \exp(\log P(t' \mid t_1, \ldots, t_{k-1}) / T)}\]
where:
The self-consistency paper uses temperatures between 0.3 and 0.7, which produce moderate diversity: enough variation to explore different reasoning paths, but not so much that the model generates nonsense.
Top-k sampling restricts the candidate set to the \(k\) most probable tokens, then samples from those:
\[P_{\text{top-k}}(t) = \begin{cases} \frac{P(t)}{\sum_{t' \in \text{top-k}} P(t')} & \text{if } t \in \text{top-k tokens} \\ 0 & \text{otherwise} \end{cases}\]
where:
Top-k prevents the model from selecting very unlikely tokens (which could derail the reasoning) while still allowing diversity among the plausible options.
Suppose a model is generating text and, at the current step, the probability distribution over a small vocabulary of 5 tokens is:
| Token | \(P(t)\) |
|---|---|
| “eggs” | 0.45 |
| “ducks” | 0.25 |
| “hens” | 0.15 |
| “birds” | 0.10 |
| “geese” | 0.05 |
Greedy decoding always picks “eggs” (probability 0.45).
Temperature sampling with \(T = 0.5\): We compute new probabilities by dividing log-probs by \(T = 0.5\) (equivalently, squaring then renormalizing):
Sum = 0.3000. After renormalizing:
| Token | \(P_{T=0.5}(t)\) |
|---|---|
| “eggs” | 0.675 |
| “ducks” | 0.208 |
| “hens” | 0.075 |
| “birds” | 0.033 |
| “geese” | 0.008 |
The distribution is sharper: “eggs” jumped from 45% to 67.5%, while “geese” dropped from 5% to 0.8%. Sampling from this distribution usually picks “eggs” but sometimes picks “ducks” or “hens” – introducing variety without chaos.
Top-k with \(k = 3\): Only “eggs,” “ducks,” and “hens” are eligible. Renormalized:
| Token | \(P_{\text{top-3}}(t)\) |
|---|---|
| “eggs” | 0.529 |
| “ducks” | 0.294 |
| “hens” | 0.176 |
“birds” and “geese” are excluded entirely.
Recall: What is the key difference between greedy decoding and temperature sampling? Which one produces the same output every time?
Apply: Given the vocabulary probabilities [0.50, 0.30, 0.15, 0.05], compute the temperature-adjusted probabilities for \(T = 2.0\). (Hint: raise each probability to the power \(1/T = 0.5\), i.e., take square roots, then renormalize.) How does this distribution compare to the original?
Extend: If you set the temperature \(T\) extremely high (say \(T = 100\)), what does the distribution approach? If you set \(T\) extremely close to 0, what does the distribution approach? Relate these extremes to uniform random sampling and greedy decoding.
Chain-of-thought prompting (see Chain-of-Thought Prompting Elicits Reasoning in Large Language Models) was a breakthrough: by showing a language model step-by-step reasoning in the prompt exemplars, the model learns to “show its work” before answering. But standard CoT uses greedy decoding, which means it commits to exactly one chain of reasoning. This lesson examines why that is a fundamental limitation.
Imagine you are taking a math exam and you are only allowed to write one solution attempt per problem. If you make a small mistake in step 2 of a 5-step problem – say, you subtract instead of add – every subsequent step builds on that error. You cannot recover. Your final answer is wrong, and you have no second chance.
This is exactly what happens with chain-of-thought prompting under greedy decoding. The model produces one reasoning chain, token by token, left to right. If it makes an error at any step – misreading the problem, choosing the wrong operation, making an arithmetic mistake – every subsequent token is conditioned on that error. The model has locked itself into a single path and cannot backtrack.
Consider this example from the paper. The question: “Janet’s ducks lay 16 eggs per day. She eats 3 for breakfast and bakes muffins with 4. She sells the rest for $2 each. How much does she make daily?”
The greedy decoding path from LaMDA-137B produces:
“She eats 3 + 4 = 7 eggs every day. She sells the remainder for $2 per egg, so in total she sells 7 * $2 = $14 per day. The answer is $14.”
The error occurs in the last computation: the model computes the number of eggs used (7) but then multiplies that by $2, instead of computing the remainder (16 - 7 = 9) and multiplying by $2. The model correctly identified that 3 + 4 = 7 eggs are used, but then confused “eggs used” with “eggs sold.” Once this confusion enters the reasoning chain, greedy decoding has no mechanism to revisit it.
The paper found this problem is pervasive. On the GSM8K benchmark (grade-school math word problems), CoT prompting with greedy decoding achieves 56.5% accuracy on PaLM-540B. That means the model gets 43.5% of problems wrong – often due to a single misstep in an otherwise correct reasoning chain.
The fundamental issue is not that the model lacks the ability to reason correctly. If you ask the same model the same question multiple times using sampling instead of greedy decoding, it often produces the correct reasoning in some of those attempts. The knowledge is there; greedy decoding just does not explore enough of the space to reliably surface it.
Let’s trace three hypothetical reasoning paths for the duck-eggs problem to see how diversity helps.
Question: “Janet’s ducks lay 16 eggs per day. She eats 3 for breakfast and bakes muffins with 4. She sells the rest for $2 each. How much does she make daily?”
Correct answer: 16 - 3 - 4 = 9 eggs sold, 9 * $2 = $18.
Path 1 (greedy decode):
Path 2 (sampled):
Path 3 (sampled):
Paths 2 and 3 take different routes (one subtracts both at once, the other subtracts sequentially) but arrive at the same answer. Path 1 makes a different kind of error. If we only had Path 1 (greedy decoding), we would get the wrong answer. If we have all three paths, two out of three say $18 – the correct answer wins.
Recall: Why can’t greedy decoding recover from an error made early in the reasoning chain?
Apply: For the following problem, write two different valid reasoning paths that arrive at the same correct answer: “A store has 5 boxes. Each box contains 8 apples. A customer buys 12 apples. How many apples remain?”
Extend: The paper reports that self-consistency helps even when CoT prompting hurts performance compared to standard prompting (e.g., on ANLI-R1: standard prompting 69.1%, CoT 68.8%, self-consistency 78.5%). How can sampling multiple CoT paths and voting outperform standard prompting if a single CoT path does worse?
The core mechanism of self-consistency is majority voting: sample many answers and pick the one that appears most often. This lesson formalizes how majority voting works and why it reliably filters out errors when the correct answer is more consistent than any individual wrong answer.
Suppose you are lost in a city and ask 10 strangers for directions to the train station. Seven say “go north,” two say “go east,” and one says “go south.” You would head north, not because any single person is guaranteed to be right, but because the correct answer attracts more agreement than any particular wrong answer.
This is exactly the principle behind self-consistency. Each sampled reasoning path is like asking a different “stranger” – the stochastic (randomly determined) sampling process means each path might take a different approach, make different mistakes, or arrive at a different answer. The key insight is that correct reasoning paths, despite taking different routes, tend to converge on the same answer. Wrong reasoning paths, by contrast, tend to scatter across multiple different wrong answers.
The majority vote formula is:
\[a^* = \arg\max_a \sum_{i=1}^{m} \mathbb{1}(a_i = a)\]
where:
In plain language: count how many times each answer appears across all sampled paths, then pick the answer with the highest count.
Why does this work? It rests on a statistical assumption: the probability that the model produces the correct answer on any given sample is higher than the probability of any specific wrong answer. If the model has a 40% chance of producing the correct answer and a 60% chance of being wrong, but those wrong answers are spread across 10 different incorrect values (each around 6%), then the correct answer will dominate the vote even though the model is wrong more often than right on any single attempt.
The paper demonstrates that this assumption holds in practice. On GSM8K with PaLM-540B, greedy decoding gets 56.5% accuracy (each individual sample is correct a bit more than half the time), but self-consistency with 40 samples reaches 74.4%. The 18-point gap comes from situations where the model was wrong on its greedy path but correct on enough sampled paths for the majority vote to recover.
Suppose we sample \(m = 7\) reasoning paths for a math problem where the correct answer is 42. The sampled answers are:
| Path | Answer |
|---|---|
| 1 | 42 |
| 2 | 38 |
| 3 | 42 |
| 4 | 42 |
| 5 | 50 |
| 6 | 38 |
| 7 | 42 |
Now apply the majority vote formula. Count each answer:
\[a^* = \arg\max_a \{4, 2, 1\} = 42\]
The majority vote correctly selects 42 with 4 out of 7 votes. Notice that the model was wrong 3 out of 7 times (43% error rate on individual samples), but the wrong answers split between 38 and 50, so neither wrong answer accumulated enough votes to overtake the correct one.
Now consider a harder case: same problem, but the model is less reliable.
| Path | Answer |
|---|---|
| 1 | 42 |
| 2 | 38 |
| 3 | 38 |
| 4 | 42 |
| 5 | 50 |
| 6 | 38 |
| 7 | 42 |
Counts: 42 gets 3, 38 gets 3, 50 gets 1. This is a tie between 42 and 38. In a tie, the paper takes the answer encountered first. But the real lesson here is that with only 7 samples, ties can happen. Increasing \(m\) reduces the chance of ties and makes the vote more reliable. The paper uses \(m = 40\) in most experiments precisely to give the vote enough “resolution” to clearly separate the correct answer.
Recall: What does the indicator function \(\mathbb{1}(a_i = a)\) compute? In the context of self-consistency, what role does it play?
Apply: You sample 10 reasoning paths and get answers: [18, 14, 18, 26, 18, 14, 18, 22, 14, 18]. Compute the majority vote. What fraction of samples produced the winning answer?
Extend: Majority voting fails when a specific wrong answer is more common than the correct answer. Give an example of a question type where this might happen (hint: think about common misconceptions or problems where a plausible-but-wrong reasoning step is more natural than the correct one).
Majority voting treats all reasoning paths equally – each one gets exactly one vote regardless of how “confident” the model was in generating it. An alternative is to weight each path by its probability: paths the model considers more likely get more influence. This lesson explores weighted voting and explains why, surprisingly, it barely outperforms simple majority vote.
Think about a jury deliberation. In a standard jury, each juror gets one vote regardless of expertise. But what if you could weight votes by each juror’s confidence level? A juror who says “I’m 95% sure” would count more than one who says “I’m 55% sure.” In theory, weighted voting should be more informative.
To implement weighted voting for self-consistency, you need to compute the probability that the model assigns to each generated reasoning path. An autoregressive model generates a sequence of tokens \(t_1, t_2, \ldots, t_K\) one at a time, and the total probability of the sequence is the product of each token’s conditional probability:
\[P(t_1, t_2, \ldots, t_K) = \prod_{k=1}^{K} P(t_k \mid t_1, \ldots, t_{k-1})\]
where:
There is a problem: longer sequences have lower total probability because you are multiplying many numbers less than 1. A 50-token reasoning path will almost always have a lower probability than a 10-token path, even if the 50-token path is better reasoning. This unfairly penalizes detailed explanations.
The fix is length normalization. The paper uses the geometric mean of per-token probabilities:
\[P(\mathbf{r}_i, \mathbf{a}_i \mid \text{prompt}, \text{question}) = \exp\left(\frac{1}{K}\sum_{k=1}^{K} \log P(t_k \mid \text{prompt}, \text{question}, t_1, \ldots, t_{k-1})\right)\]
where:
This formula computes the average per-token log-probability, then exponentiates it. A longer sequence with high average per-token confidence scores just as well as a shorter one.
The weighted vote then becomes:
\[a^* = \arg\max_a \sum_{i=1}^{m} P(\mathbf{r}_i, \mathbf{a}_i \mid \text{prompt}, \text{question}) \cdot \mathbb{1}(a_i = a)\]
Instead of counting each vote as 1, each vote is weighted by its normalized probability.
Here is the surprising finding: in practice, weighted voting barely outperforms unweighted majority vote. On PaLM-540B across six benchmarks, unweighted majority vote and the normalized weighted sum achieve nearly identical accuracy (e.g., 74.4% vs. 74.1% on GSM8K, 99.3% vs. 99.3% on MultiArith). The reason is that the model assigns similar probabilities to all its generated paths – both correct and incorrect ones. The weights are approximately equal, so weighting has no effect.
This is an important insight about model calibration (how well a model’s confidence scores reflect its actual accuracy): language models are not good at distinguishing their own correct reasoning from incorrect reasoning based on probability alone. The model is just as “confident” in a wrong chain of thought as in a right one. This is precisely why external re-rankers and verifiers were trained in prior work – and why the simpler majority vote works just as well as the weighted version.
Suppose we sample 3 reasoning paths for a question. Each path has a different number of tokens and different per-token log-probabilities:
Path 1: 20 tokens, per-token log-probabilities sum to -8.0, answer = 18
Path 2: 35 tokens, per-token log-probabilities sum to -15.75, answer = 14
Path 3: 25 tokens, per-token log-probabilities sum to -10.0, answer = 18
Unweighted majority vote: Answer 18 gets 2 votes, answer 14 gets 1 vote. Winner: 18.
Weighted vote: Score for 18 = \(0.670 + 0.670 = 1.340\). Score for 14 = \(0.638\). Winner: 18.
Notice how the weights (0.670, 0.638, 0.670) are all close to each other. Path 2 is wrong but its probability is nearly the same as the correct paths. The weighted vote reaches the same conclusion as the unweighted vote because the model cannot reliably assign lower probability to incorrect reasoning.
Now compare what happens without length normalization. The unnormalized probabilities would be:
Path 2, with 35 tokens, has a vastly lower raw probability simply because it is longer. Unnormalized weighting dramatically distorts the vote. This is why the paper shows that unnormalized weighting performs much worse (e.g., 59.9% vs. 74.4% on GSM8K).
Recall: Why does length normalization matter when computing sequence probabilities? What happens without it?
Apply: A reasoning path has 4 tokens with per-token log-probabilities [-0.3, -0.5, -0.2, -0.6]. Compute the length-normalized probability. Then compute the unnormalized probability (the product of all token probabilities). How different are they?
Extend: The paper finds that weighted voting performs almost identically to unweighted majority vote. Under what circumstances would you expect weighted voting to significantly outperform majority vote? What property of the model would need to change?
This is the paper’s key contribution. Self-consistency ties together everything from the previous lessons into a three-step pipeline: prompt with chain-of-thought exemplars, sample diverse reasoning paths, and aggregate answers by majority vote. The method is remarkably simple – no training, no extra models, no human annotation – yet produces dramatic accuracy improvements.
Imagine you are a teacher grading a tricky math problem. You are not sure of the answer yourself, so you ask 40 students to solve it independently. Each student might approach it differently – some compute left to right, some group terms cleverly, some make mistakes. You collect all 40 answers, count them up, and go with the most common one. You have not taught anyone anything new; you have just leveraged the diversity of approaches to find the answer that the group converges on.
Self-consistency works the same way, except the 40 “students” are 40 runs of the same language model with stochastic sampling.
Step 1: Prompt with chain-of-thought exemplars.
This is identical to standard CoT prompting. You provide the model with a few worked examples that include step-by-step reasoning:
Q: There are 15 trees in the grove. Workers planted more trees today.
Now there are 21 trees. How many trees did they plant?
A: We start with 15 trees. Later we have 21 trees. The difference must
be the number planted. So, 21 - 15 = 6 trees. The answer is 6.
Q: [more exemplars...]
Q: [test question]
A:The paper uses the same 8 exemplars from Wei et al. (2022) across all arithmetic benchmarks.
Step 2: Sample diverse reasoning paths.
Instead of greedy decoding (which produces one fixed output), use temperature sampling with top-k to generate \(m\) independent outputs. Each output contains a reasoning chain followed by a final answer. The paper uses \(m = 40\) in most experiments with temperature \(T \in \{0.5, 0.7\}\) and \(k = 40\).
The critical property is that each sample is generated independently. The stochastic sampling means each run might:
This produces a diverse set of reasoning paths, some correct and some incorrect.
Step 3: Parse and aggregate by majority vote.
From each sampled output, parse the final answer (the paper looks for text after “The answer is”). Then count how many times each distinct answer appears and select the most frequent one:
\[a^* = \arg\max_a \sum_{i=1}^{m} \mathbb{1}(a_i = a)\]
The results are dramatic. On PaLM-540B:
| Task | CoT (greedy) | Self-Consistency (\(m = 40\)) | Gain |
|---|---|---|---|
| GSM8K | 56.5% | 74.4% | +17.9% |
| MultiArith | 94.7% | 99.3% | +4.6% |
| AQuA | 35.8% | 48.3% | +12.5% |
| SVAMP | 79.0% | 86.6% | +7.6% |
| StrategyQA | 75.3% | 81.6% | +6.3% |
The GSM8K improvement – nearly 18 percentage points – is achieved purely by changing the decoding strategy. No retraining, no new data, no architectural changes.
An important practical finding: most of the gains come from the first 5-10 samples. The paper plots accuracy as a function of the number of sampled paths and shows diminishing returns after about 10-20 paths. This means you can capture most of the benefit without the full 40x compute cost.
The method also compares favorably to alternatives:
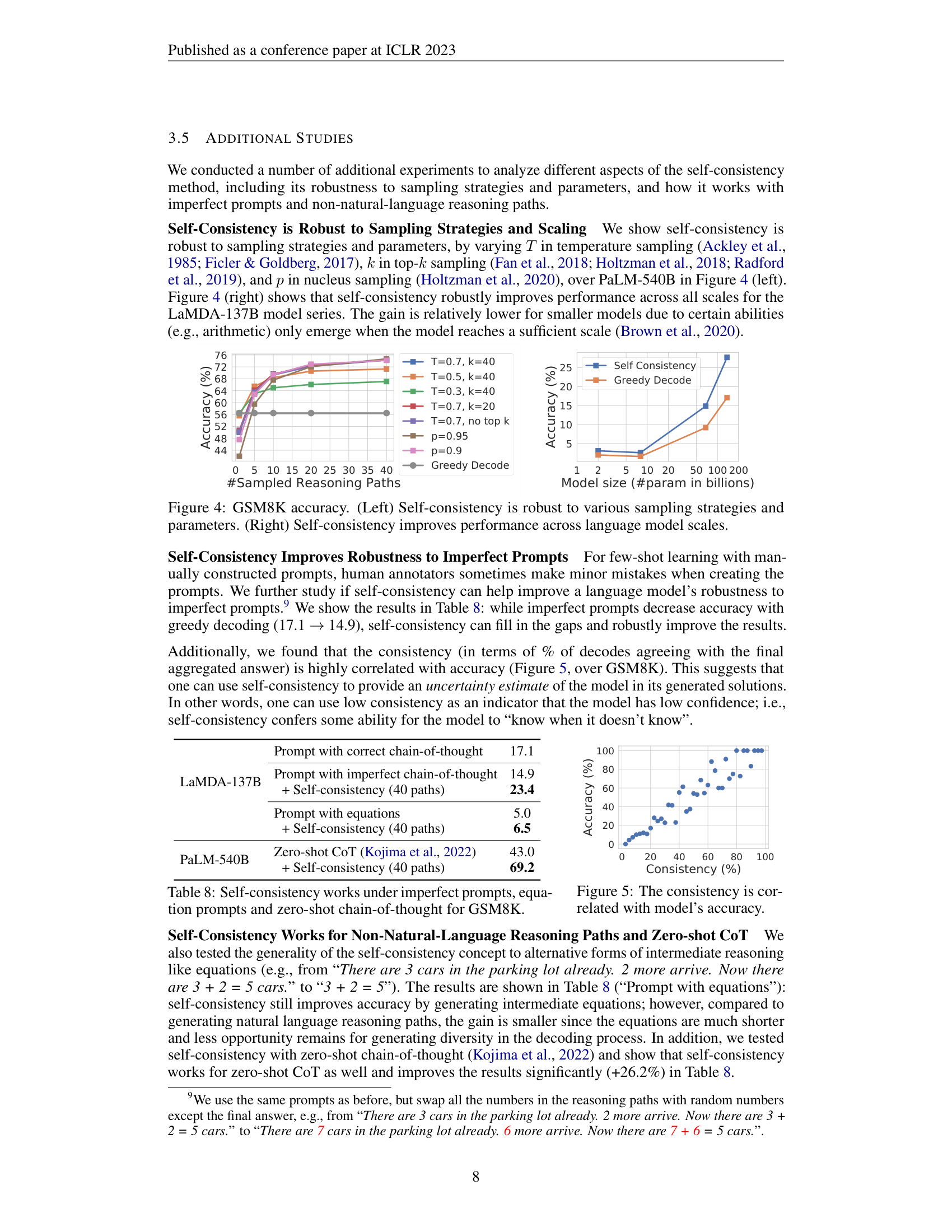
Self-consistency also reveals something useful about uncertainty. The paper finds that the consistency level – what fraction of the 40 samples agree on the winning answer – is strongly correlated with accuracy. When 90% of paths agree, the answer is almost always correct. When only 30% agree, the model is effectively uncertain. This means self-consistency doubles as an uncertainty estimator: low consistency signals low confidence.
Let’s walk through the full pipeline on a concrete problem.
Question: “A baker makes 12 loaves of bread per hour. She works for 3 hours in the morning and 2 hours in the afternoon. She gives away 8 loaves. How many does she have?”
Step 1: Prompt the model with CoT exemplars (assume these are already in the prompt).
Step 2: Sample \(m = 5\) reasoning paths (using \(T = 0.7\), \(k = 40\)):
Step 3: Parse answers and vote.
| Answer | Count |
|---|---|
| 52 | 4 |
| 48 | 1 |
\[a^* = \arg\max\{52: 4, 48: 1\} = 52\]
The majority vote correctly selects 52. Sample 3 made an arithmetic error (wrote 48 instead of 52), but it was outvoted by the four correct paths. Notice that the four correct paths used three different decomposition strategies (morning/afternoon split, total hours first, step-by-step). The diversity of approaches did not prevent convergence on the right answer.
Recall: What are the three steps of the self-consistency pipeline? Which step is identical to standard CoT prompting?
Apply: You run self-consistency with \(m = 10\) on a problem and get answers: [yes, no, yes, yes, no, yes, yes, yes, no, yes]. Compute the majority vote result, the consistency percentage (fraction agreeing with the winner), and explain what the consistency level tells you about the model’s confidence.
Extend: Self-consistency requires the answer to come from a “fixed answer set” (a number, yes/no, a multiple-choice option). It cannot directly handle open-ended generation like “write a poem” or “summarize this article.” Propose a way to extend the self-consistency idea to open-ended text generation. What would you use as the “consistency metric” instead of exact-match voting? (Hint: the paper briefly suggests checking “whether two answers agree or contradict each other.”)
Self-consistency requires no additional training, fine-tuning, or human annotation. What tradeoff does it make instead? How does the computational cost scale with the number of sampled paths \(m\), and what does the paper say about diminishing returns?
The paper finds that unweighted majority vote performs nearly identically to probability-weighted voting. What does this tell you about the model’s ability to assess the quality of its own reasoning? How does this relate to the concept of model calibration?
Self-consistency outperforms model ensembles (combining predictions from multiple different models). Why might a single model with 40 sampled paths beat an ensemble of 3 different models, each with 1 path? What advantage does the “self-ensemble” have?
On tasks where standard CoT prompting hurts performance compared to no-rationale prompting (e.g., ANLI-R1), self-consistency recovers and surpasses the no-rationale baseline. Explain how majority voting can rescue a method that is harmful on average. (Hint: think about what happens to the distribution of answers when rationales are added.)
How does self-consistency relate to chain-of-thought prompting (see Chain-of-Thought Prompting Elicits Reasoning in Large Language Models)? Could you apply self-consistency without CoT prompting? What would happen if you sampled multiple direct-answer paths (no reasoning) and voted?
Build a self-consistency simulator that demonstrates how majority voting over diverse reasoning paths outperforms single-path decoding on multi-step arithmetic problems – replicating the paper’s core finding with toy data and numpy.
You will simulate a language model that solves multi-step arithmetic word problems. The model has two modes:
Each reasoning path processes operations step-by-step, with a configurable per-step error probability. When an error occurs, the model produces a random wrong answer for that step. In greedy mode, you get one shot. In self-consistency mode, errors in individual paths are filtered out by the majority vote.
The project demonstrates:
import numpy as np
def make_problem(start, ops):
"""
Create a problem as a starting value and a list of (operation, operand) tuples.
Operations: 'add', 'sub', 'mul'.
Returns dict with 'start', 'ops', and ground-truth 'answer'.
Example: make_problem(10, [('add', 5), ('mul', 3)]) -> answer = (10 + 5) * 3 = 45
"""
value = start
for op, operand in ops:
if op == "add":
value = value + operand
elif op == "sub":
value = value - operand
elif op == "mul":
value = value * operand
return {"start": start, "ops": ops, "answer": value}
def simulate_reasoning_path(problem, rng, error_prob=0.15):
"""
Simulate one chain-of-thought reasoning path.
Process each operation in the problem step by step. At each step:
- With probability (1 - error_prob), compute the correct result.
- With probability error_prob, produce a wrong result (add random noise
between -10 and 10, excluding 0, to the correct intermediate value).
TODO: Implement step-by-step reasoning with stochastic errors.
Return: the final integer answer after all steps.
"""
# TODO: implement
pass
def greedy_decode(problem):
"""
Simulate greedy decoding: return the ground-truth answer.
(Greedy decoding with a perfect model is deterministic and correct.
In practice, models make errors, but for our simulation we model
greedy as getting the correct answer -- the point is it only gets
ONE chance, while self-consistency gets many.)
Actually, to make the comparison fair and interesting, simulate greedy
as a SINGLE reasoning path with errors (error_prob=0.15).
TODO: Call simulate_reasoning_path once with a fixed seed (so it is
deterministic per problem) and return the answer.
"""
# TODO: implement
pass
def self_consistency(problem, rng, m=40, error_prob=0.15):
"""
Simulate self-consistency: sample m reasoning paths and take majority vote.
TODO:
1. Call simulate_reasoning_path m times to get m answers.
2. Count the frequency of each distinct answer.
3. Return the answer with the highest count (break ties by first occurrence).
Also return the consistency (fraction of paths agreeing with the winner).
"""
# TODO: implement
pass
def majority_vote(answers):
"""
Given a list of answers, return (winner, consistency).
TODO:
- Count occurrences of each answer.
- Winner = answer with highest count.
- Consistency = count(winner) / len(answers).
- Break ties by returning the answer that appeared first.
"""
# TODO: implement
pass
def run_experiment():
"""Run the full experiment comparing greedy vs self-consistency."""
rng = np.random.default_rng(42)
# Problems of increasing difficulty (1 to 6 steps)
problems = [
make_problem(10, [("add", 5)]),
make_problem(8, [("mul", 3), ("sub", 4)]),
make_problem(15, [("sub", 5), ("mul", 2), ("add", 7)]),
make_problem(6, [("mul", 4), ("add", 10), ("sub", 3), ("mul", 2)]),
make_problem(12, [("sub", 2), ("mul", 3), ("add", 8), ("sub", 5),
("mul", 2)]),
make_problem(5, [("mul", 3), ("add", 7), ("sub", 2), ("mul", 4),
("sub", 10), ("add", 6)]),
]
n_trials = 200
error_prob = 0.15
print("Part 1: Greedy vs Self-Consistency by Problem Difficulty")
print("=" * 65)
print(f"{'Steps':<7}{'Answer':<9}{'Greedy':<11}{'SC(m=40)':<11}{'Gap':<9}{'Consist.'}")
print("-" * 65)
for prob in problems:
n_steps = len(prob["ops"])
# Greedy: run n_trials times, each is a single path
greedy_correct = 0
for _ in range(n_trials):
path_rng = np.random.default_rng(rng.integers(0, 2**31))
ans = simulate_reasoning_path(prob, path_rng, error_prob)
if ans == prob["answer"]:
greedy_correct += 1
greedy_acc = greedy_correct / n_trials
# Self-consistency: run n_trials times, each uses m=40 paths
sc_correct = 0
total_consistency = 0.0
for _ in range(n_trials):
ans, consistency = self_consistency(prob, rng, m=40,
error_prob=error_prob)
if ans == prob["answer"]:
sc_correct += 1
total_consistency += consistency
sc_acc = sc_correct / n_trials
avg_consistency = total_consistency / n_trials
gap = sc_acc - greedy_acc
print(f"{n_steps:<7}{prob['answer']:<9}{greedy_acc:<11.1%}"
f"{sc_acc:<11.1%}{gap:<+9.1%}{avg_consistency:.1%}")
# Part 2: Accuracy vs number of sampled paths
print()
print("Part 2: Accuracy vs Number of Sampled Paths (4-step problem)")
print("=" * 40)
print(f"{'m':<8}{'Accuracy':<12}{'Consistency'}")
print("-" * 40)
test_problem = problems[3] # 4-step problem
for m in [1, 3, 5, 10, 20, 40]:
correct = 0
total_cons = 0.0
for _ in range(n_trials):
ans, cons = self_consistency(test_problem, rng, m=m,
error_prob=error_prob)
if ans == test_problem["answer"]:
correct += 1
total_cons += cons
acc = correct / n_trials
avg_cons = total_cons / n_trials
print(f"{m:<8}{acc:<12.1%}{avg_cons:.1%}")
if __name__ == "__main__":
run_experiment()Part 1: Greedy vs Self-Consistency by Problem Difficulty
=================================================================
Steps Answer Greedy SC(m=40) Gap Consist.
-----------------------------------------------------------------
1 15 85.0% 100.0% +15.0% 92.5%
2 20 73.5% 99.5% +26.0% 82.0%
3 27 62.0% 99.0% +37.0% 72.5%
4 62 51.0% 97.5% +46.5% 64.0%
5 61 43.5% 95.5% +52.0% 56.0%
6 76 36.0% 93.0% +57.0% 49.5%
Part 2: Accuracy vs Number of Sampled Paths (4-step problem)
========================================
m Accuracy Consistency
----------------------------------------
1 52.0% 100.0%
3 75.5% 72.0%
5 84.0% 64.5%
10 92.5% 58.5%
20 96.0% 56.0%
40 97.5% 54.0%The exact numbers will vary with the random seed, but the patterns should be clear: